
The DevOps Revolution
The DevOps revolution has taken hold, at least in concept, in a broad range of organizations. In the more advanced organizations, there are teams of Agile-certified scrum masters. IT line staff and managers are trained in the principles, and they typically manage their work in software suites like JIRA, Azure DevOps, and ServiceNow. The process investment in most cases is significant.
Often these practices are successful in individual teams, achieving the increased throughput and rapid feature development for certain applications. Even in these cases, however, the organization-wide transformation remains elusive. Process victories are isolated to proof of concept initiatives, and the understanding of progress remains hidden at upper levels of management. The end result is that the goal of ten releases per day feels just as far away as it did in the waterfall era, and the return on the investment in Agile practices is impossible to assess.
Make DevOps Visible
An important first step is measuring adherence to the DevOps process. DevOps is not a shackle, but it contains a number of counterintuitive practices that require radical change for development teams. Reducing batch size means breaking work into much smaller deliverables, which can be a real shift for developers that enjoy wrestling with complexity. Respecting the sanctity of sprints means turning down requests from vocal and insistent internal customers, which requires a different discipline for developers that want to please and derive a sense of pride from being able to build anything. These few examples stand in for many, each giving rise to real resistance to adoption.
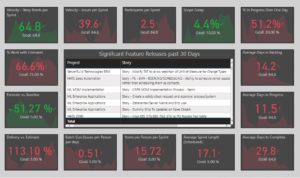
You get what you measure. Teams following the new practices need to be praised and recognized. In order for management to do so, it is critical to have reliable metrics on these behaviors that evaluate team and individual performance. The good news is that the data required to calculate these metrics are captured in the systems that manage this work and that DevOps is a mature enough practice that consensus around the metrics has been established. The bad news is that the data has rarely been consolidated and presented to management in a reliable and actionable medium. We do have some good news on that front below.
Elevate Bottlenecks
The key to achieving increased velocity and throughput for application development as well as for any production process is the ability to identify and remove bottlenecks in the production process. In a manufacturing shop, the identification process is relatively easy. A manager can walk around the shop floor and see where inventory is piling up. This is the bottleneck.
In software, we don’t have physical inventory, but we do have work in progress. We can see this backlogged work in individual assignment queues. The nice thing here is that we don’t have to walk around. All the work is tracked within our project management systems.
Let’s take a moment to state that bottleneck is not a dirty word. The bottleneck in any IT process is almost always the rock star of the group. For example, let’s talk about our star developer David Lee. Everybody Wants Some David Lee on their task. Whether it’s developing the capability of their Dreams, a particularly risky change implementation, or a critical incident Eruption, David Lee is the go-to guy. What eventually happens is that all work is waiting on David Lee to complete it. David Lee, despite his best efforts and supernatural energy, is the bottleneck for the organization.
What management needs to do is alleviate the bottleneck by assigning these tasks to other people. That means making the difficult decision of assigning a critical incident to someone who will take longer to address it, assigning a change implementation to someone with less familiarity with the application, or farming development tasks, though critical, to one or more team members that will take twice as long to complete them.
These are all decisions that seem career limiting unless the bottleneck is identified and it can be communicated to management that sub-optimizing these individual tasks will increase the throughput for the organization as a whole. It’s even likely that each task will be completed earlier than if the rock star himself were working on it since they don’t have to say I’ll Wait for David Lee to Jump.
One of the problems here is that the development work queues and service work queues (incidents and changes) typically reside in different systems, so it becomes difficult to evaluate and compare the total value of the work queue. If only somebody had a solution. For some good news on that topic, click the graph below and let us show you how it works.
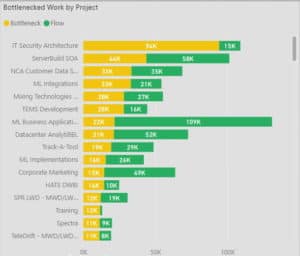
Rock on!